
Woodler is Hiring!!!
by Michal Tinthofer on 23/08/2019Do you love SQL Server? WOODLER hiring new staff...
Read moreWe recently resolved a critical performance issue where a client reported an unusual spike in HADR_SYNC_COMMIT wait types. This state indicated that transactions on the primary node were experiencing significant delays while waiting for hardening confirmations from the secondary node within an Always On Availability Group (AG).
Phase 1: Detailed Monitoring & Identification
To pinpoint the bottleneck, we implemented a three-tier testing strategy:
The Findings: 595-Second Latencies
The evaluation revealed that the issue wasn't within SQL Server itself, but rather a massive throughput limitation in the network:
Root Cause: The "100 Mbit" Trap
A physical infrastructure audit revealed that 2 out of 4 paths to the secondary node had downgraded to 100 Mbit speed. Furthermore, since the AG Endpoints were configured using FQDNs resolving to Public IPs, the SQL traffic was routing through the "Public" interface (Team #1) instead of the intended high-speed Private team (Team #2).
.png)
.png)
Proposed Solutions & Final Implementation
We presented the client with two options:
The client chose Option 2. Combined with a core switch upgrade, the 4x1Gbit links were decommissioned, and the nodes were connected via 2x10Gbit interfaces to dedicated Dell switches using an untagged VLAN for internal cluster traffic.
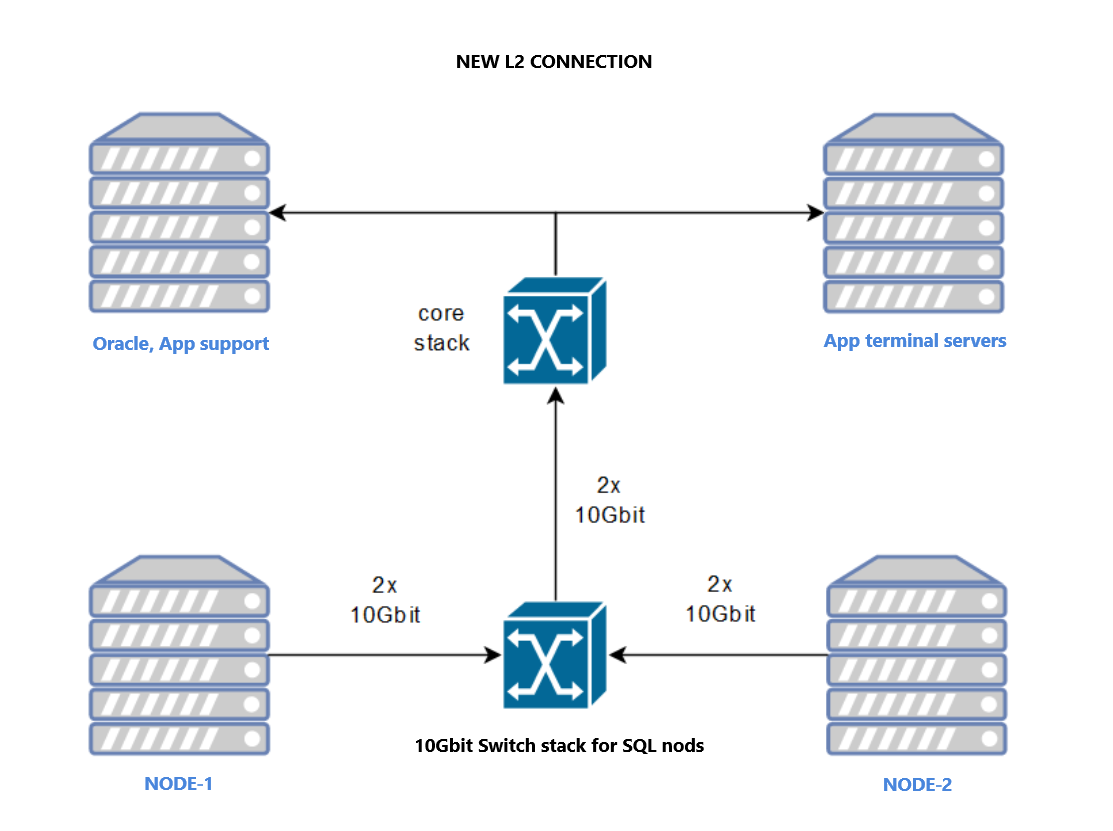
Conclusion
Post-implementation, the HADR_SYNC_COMMIT wait times dropped to zero. This case serves as a reminder: even the most optimized SQL Server instance cannot outperform a degraded or misconfigured network layer.
Michal is a technically proficient SQL Server Specialist with a proven track record in resolving incidents and implementing changes within large-scale database infrastructures, ensuring maximum availability of services. Concurrently, as a Digital Content and Marketing Specialist, his priority is building strong online brand identities through strategic communication and creative storytelling. He consistently seeks new ways to enhance digital interaction, believing quality digital communication is key to success in today's connected world.
Do you love SQL Server? WOODLER hiring new staff...
Read moreNew version has been released and more features than we planned initially made it in.
Read moreYou open your performance analytics tool to check the top wait types, expecting the usual suspects like PAGEIOLATCH or CXPACKET. Instead, staring back at you is a strange, rarely seen wait type: PREEMPTIVE_OS_QUERYREGISTRY.
Read more




